CUDA image 처리
회사서 간단하게 발표자료를 만들면서 쿠다 프로그래밍을 해보았습니다.
근데 node회사라는게 함정입니다.
간단한 영상을 미러링 해주는 프로그램입니다.
#include <iostream>
#include <iostream>
#include <chrono>
#include <vector>
#include <thread>
#include "bitmap_image.hpp"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
// GTX 1060 thread Count is 128
#define THREAD_SIZE_X 32
#define THREAD_SIZE_Y 4
bitmap_image gpuToBitImage(uchar4* gpuPoint, int row, int col);
uchar4* gpuLoad(bitmap_image& image) {
std::vector<uchar4> imageBuket;
size_t size = image.width() * image.height();
imageBuket.reserve(size);
for (int y = 0; y < image.height(); ++y) {
for (int x = 0; x < image.width(); ++x) {
rgb_t colour;
image.get_pixel(x, y, colour);
imageBuket.push_back({ colour.red,colour.green,colour.blue,0 });
}
}
uchar4* gpuMmeory = nullptr;
cudaMalloc((void**)&gpuMmeory, sizeof(uchar4) * image.width() * image.height());
cudaMemcpy(gpuMmeory, &(imageBuket[0]), sizeof(uchar4) * image.width() * image.height(), cudaMemcpyHostToDevice);
return gpuMmeory;
}
__global__
void mirror(const uchar4* org, uchar4* result, int row, int col) {
int tCol = blockDim.x * blockIdx.x + threadIdx.x;
int tRow = blockDim.y * blockIdx.y + threadIdx.y;
if (tCol >= col || tRow >= row) {
return;
}
int posion = tRow * col + tCol;
int resultPosion = (tRow * col) + (col - tCol);
result[resultPosion] = org[posion];
}
bitmap_image gpuToBitImage(uchar4* gpuPoint, int col, int row) {
bitmap_image image(col, row);
std::vector<uchar4> imageBuket;
imageBuket.resize(row * col);
cudaMemcpy(&(imageBuket[0]), gpuPoint, sizeof(uchar4) * row * col, cudaMemcpyDeviceToHost);
for (int y = 0; y < image.height(); ++y)
{
for (int x = 0; x < image.width(); ++x)
{
uchar4 color = imageBuket[(y * col) + x];
image.set_pixel(x, y, color.x, color.y, color.z);
}
}
return image;
}
bitmap_image mirrorImple(bitmap_image& image) {
uchar4* gpuPoint = gpuLoad(image);
uchar4* gpuResultPoint;
cudaMalloc((void**)&gpuResultPoint, sizeof(uchar4) * image.width() * image.height());
dim3 thread(THREAD_SIZE_X, THREAD_SIZE_Y);
dim3 grid(
(image.width() / THREAD_SIZE_X) + 1,
(image.height() / THREAD_SIZE_Y) + 1
);
mirror << <grid, thread >> > (gpuPoint, gpuResultPoint, image.height(), image.width());
bitmap_image result = gpuToBitImage(gpuResultPoint, image.width(), image.height());
cudaFree(gpuPoint);
cudaFree(gpuResultPoint);
return result;
}
int main()
{
bitmap_image image("image.bmp");
if (!image)
{
printf("Error - Failed to open: input.bmp\n");
return 1;
}
bitmap_image result = mirrorImple(image);
result.save_image("asdsad.bmp");
return 0;
}실행 결과는 아래와 같습니다.
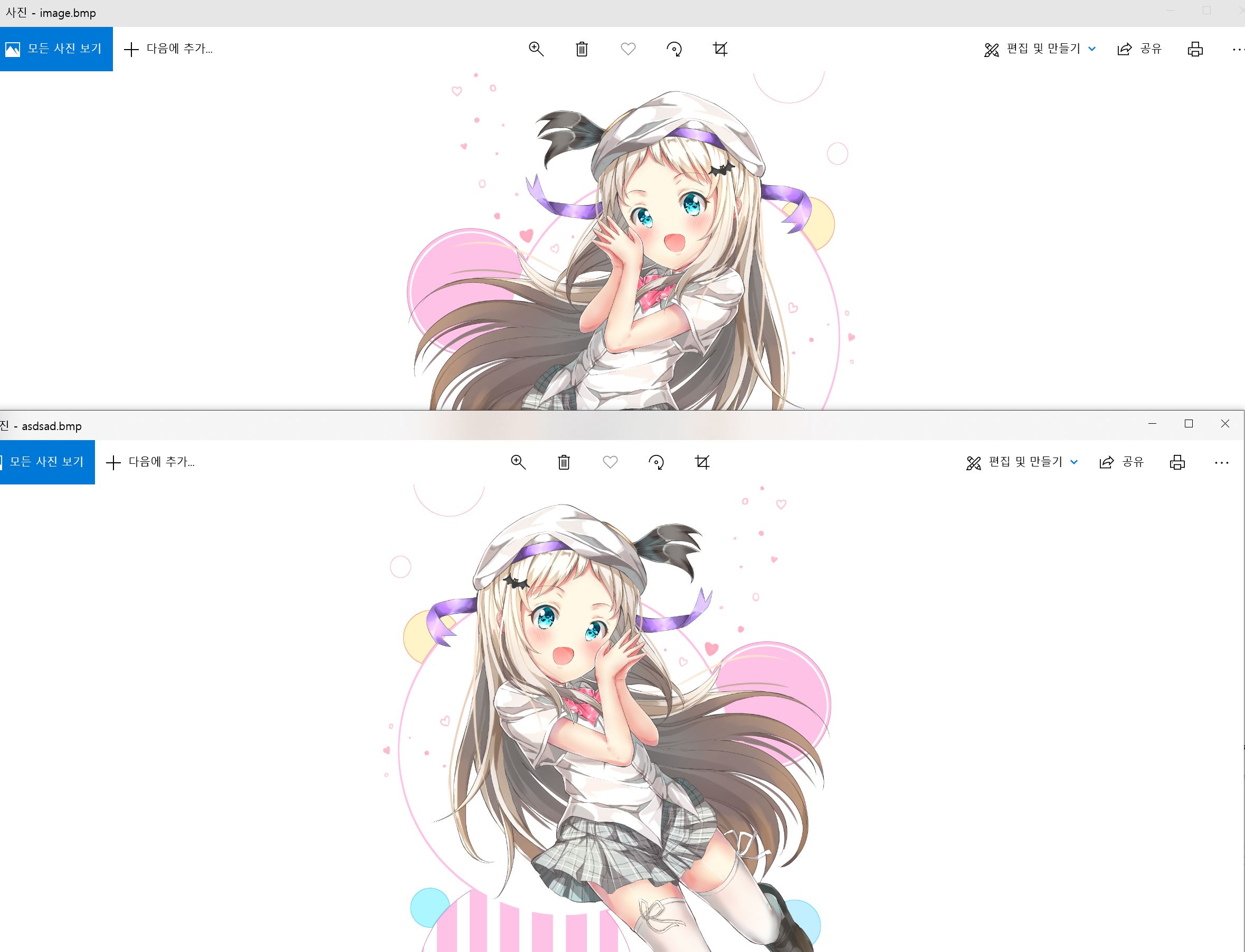
가우시안 블루같은경우도 해당 코드를 가져가서 사용하면 쉽게(?) 사용할수 있을것입니다.
이미지 처리는 아래 bitmap이미지를 사용했습니다.
https://github.com/ArashPartow/bitmap/blob/master/bitmap_image.hpp
1060 GTX가 블록단 스레드가 128이 한계라서 스레드 사이즈를 32 * 4로 하였습니다.
Warp단위라 속도가 빠를겁니다.